

Mixture-of-Experts: Konon Jadi Senjata DeepSeek Makin Cerdas!

Pernahkah kamu berpikir bagaimana model AI bisa menjadi begitu pintar dalam memahami berbagai jenis data? Salah satu teknik canggih yang digunakan adalah Mixture-of-Experts (MoE). Teknologi ini kabarnya mengambil peran kunci yang membuat DeepSeek lebih cerdas dari model AI lainnya.
Dalam artikel ini, kita akan membahas apa itu MoE, cara kerjanya, penerapannya, serta perannya dalam pengembangan DeepSeek.
Apa Itu Mixture-of-Experts?
Bayangkan sebuah model AI seperti sebuah tim spesialis, di mana setiap anggota memiliki keahlian uniknya sendiri. Di sinilah Mixture-of-Experts hadir!
Mixture-of-Experts (MoE) bekerja berdasarkan prinsip ini dengan membagi tugas kompleks ke dalam beberapa jaringan kecil yang disebut “experts” atau “ahli”.
Setiap expert fokus pada bagian tertentu dari masalah, memungkinkan model bekerja lebih efisien dan akurat. Ini mirip dengan dunia nyata: kita pergi ke dokter untuk masalah kesehatan, mekanik untuk mobil, dan koki untuk masakan.
Dengan sistem ini, AI dapat menangani berbagai permasalahan dengan lebih baik dibandingkan model AI yang hanya bersifat generalis.
Baca Juga: Deep Learning Adalah: Cara Kerja, Manfaat dan Aplikasinya
Bagaimana Cara Kerja MoE?
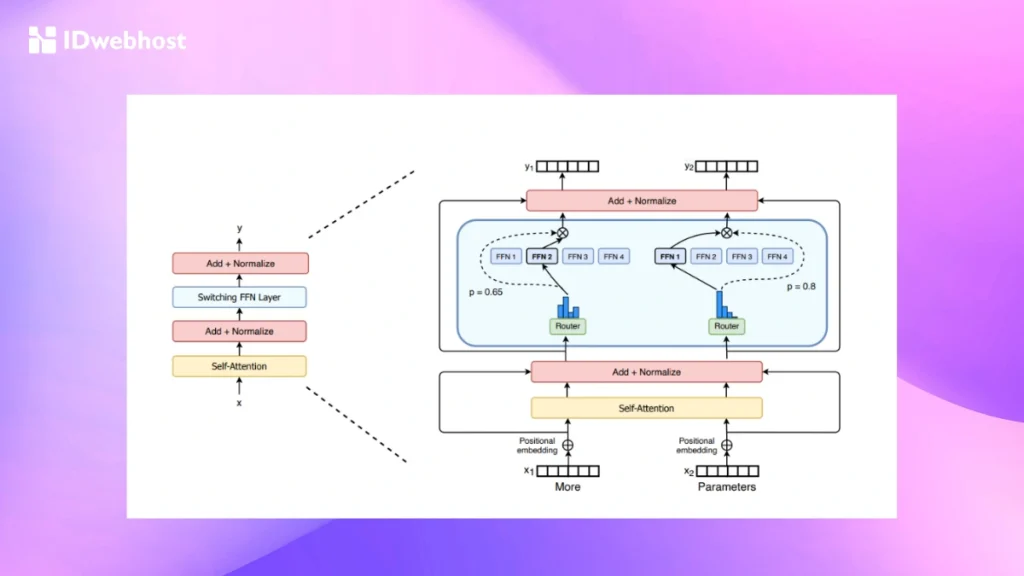
MoE beroperasi dalam dua tahap utama:
Tahap 1: Training Phase (Tahap Pelatihan)
Seperti model machine learning lainnya, MoE dimulai dengan pelatihan pada dataset tertentu.
Namun, yang membedakan adalah pelatihannya dilakukan secara terpisah pada masing-masing expert, yakni:
- Expert Training: Setiap expert dilatih menggunakan subset data yang sesuai dengan tugasnya. Misalnya, dalam pemrosesan bahasa alami (Natural Language Processing/NLP), satu expert bisa fokus pada sintaksis sementara yang lain fokus pada semantik.
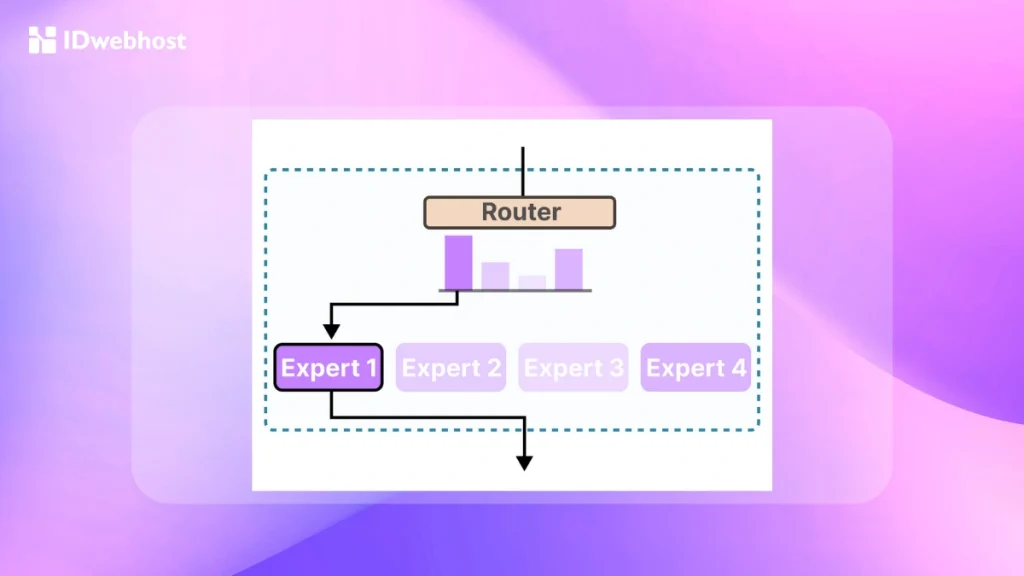
- Gating Network Training: Gating network bertugas memilih expert terbaik untuk setiap input yang masuk. Jaringan ini dilatih untuk memahami distribusi probabilitas atas para expert, sehingga dapat menentukan mana yang paling sesuai dengan tugas yang diberikan.
- Joint Training: Setelah semua komponen dilatih, seluruh sistem MoE disempurnakan secara bersama-sama. Proses ini mengoptimalkan kerja sama antara expert dan gating network untuk meningkatkan performa model.
Tahap 2: Inference Phase (Tahap Inferensi)
Inferensi adalah tahap di mana model menggunakan hasil pelatihannya untuk memproses input baru. Proses ini terdiri dari beberapa langkah:
- Input Routing: Gating network mengevaluasi input dan menentukan expert mana yang paling cocok untuk menangani tugas tersebut.
- Expert Selection: Hanya beberapa expert yang dipilih untuk memproses input. Ini membantu menghemat sumber daya komputasi sekaligus memanfaatkan keahlian spesifik dalam model.
- Output Combination: Output dari expert yang dipilih dikombinasikan menggunakan teknik seperti weighted averaging, voting, atau metode kombinasi lainnya untuk menghasilkan prediksi akhir yang lebih akurat.
Dengan pendekatan ini, MoE mampu meningkatkan efisiensi dan akurasi tanpa membebani sumber daya komputasi secara berlebihan.
Baca Juga: Cara Menggunakan Hugging Face: Apa Saja Fitur & Manfaatnya?
Penerapan MoE di Bidang Machine Learning
MoE bukanlah teknologi baru. Sebenarnya, konsep ini telah dikembangkan selama lebih dari 30 tahun dan digunakan di berbagai bidang machine learning, seperti:
Natural Language Processing (NLP)
MoE digunakan dalam model bahasa besar untuk meningkatkan efisiensi dan kecepatan inferensi.
Contohnya adalah Microsoft’s translation API, Z-code, yang menggunakan MoE untuk menangani skala model yang besar dengan tetap menjaga konsumsi komputasi tetap rendah.
Computer Vision
Google menggunakan MoE dalam Vision Transformers (ViT) untuk mendukung tugas-tugas pengenalan gambar.
V-MoEs memungkinkan pemrosesan gambar yang lebih efisien dengan membagi gambar menjadi bagian-bagian kecil yang diproses oleh expert khusus.
Sistem Rekomendasi
MoE juga digunakan dalam sistem rekomendasi, seperti algoritma ranking video YouTube berbasis Multi-Gate MoE (MMoE).
MoE membantu mengelompokkan rekomendasi berdasarkan kategori yang berbeda, seperti keterlibatan pengguna dan kepuasan.
Karena keunggulannya dalam efisiensi dan skalabilitas, MoE banyak diadopsi dalam industri AI. Salah satu implementasi menarik dari MoE adalah dalam pengembangan DeepSeek.
Baca Juga: BERT AI Model: Pahami Cara Kerja dan Bedanya dengan GPT
Peran MoE dalam Pengembangan DeepSeek
Saat ini model AI semakin canggih berkat teknologi Mixture-of-Experts. Nah, salah satu model AI yang berhasil membuktikannya adalah DeepSeek.
Teknologi asal China ini merilis DeepSeek-V2, model berbasis MoE yang punya 236 miliar parameter dan mampu memproses hingga 128 ribu token. Ini memungkinkan model lebih efisien dalam menangani tugas kompleks.
DeepSeek terus mengembangkan MoE dengan menghadirkan DeepSeekMoE, yang membagi spesialisasi ahli secara lebih cerdas.
Artinya, AI bisa memilih “pakar” terbaik untuk tugas tertentu, meningkatkan akurasi tanpa membebani komputasi.
Bahkan, DeepSeek merambah dunia multimodal lewat DeepSeek-VL2, yang memproses teks dan gambar secara optimal. Pendekatan ini membawa beberapa manfaat:
- Efisiensi Sumber Daya: DeepSeek mengurangi biaya komputasi dengan hanya mengaktifkan expert yang diperlukan, membuat model AI besar lebih terjangkau dan dapat diakses oleh lebih banyak pengguna.
- Presisi Tugas-Spesifik: DeepSeek dapat menangani berbagai jenis input dengan akurasi tinggi, berkat spesialisasi yang diterapkan dalam modelnya.
- Skalabilitas: DeepSeek dapat dengan mudah diperbesar dengan menambahkan expert baru tanpa meningkatkan beban komputasi secara signifikan.
Selain itu, DeepSeek memiliki beberapa strategi unik dalam implementasi MoE:
- Fine-grained Expert Segmentation: Setiap expert dibagi menjadi bagian lebih kecil untuk meningkatkan spesialisasi.
- Shared Expert Isolation: Beberapa expert selalu aktif untuk menangani pengetahuan umum yang diperlukan dalam berbagai konteks.
- Expert Choice (EC) Routing Algorithm: Algoritma ini memastikan beban kerja antar expert merata, mencegah under-utilization atau overload.
- Penggantian Feed-Forward Network (FFN) dengan MoE Layers: DeepSeek menggunakan sparse MoE layers untuk meningkatkan kapasitas dengan biaya komputasi yang lebih rendah.
- Pengurangan Redundansi Pengetahuan: DeepSeek menghindari tumpang tindih antara expert untuk meningkatkan efisiensi dan spesialisasi.
Dengan arsitektur MoE yang canggih, DeepSeek menjadi salah satu model AI paling efisien saat ini. Lalu, apa saja manfaat umum dari MoE?
Baca Juga: DeepSeek R1 vs DeepSeek V3: Mana yang Lebih Unggul?
Manfaat MoE
Menggunakan Mixture-of-Experts dalam pengembangan Model AI memberikan berbagai keuntungan:
- Performa Tinggi: Dengan hanya mengaktifkan expert yang relevan, MoE mengurangi konsumsi sumber daya dan meningkatkan kecepatan inferensi.
- Fleksibilitas: MoE memungkinkan model AI menangani berbagai jenis tugas dengan lebih akurat.
- Toleransi terhadap Kesalahan: Jika satu expert mengalami masalah, model secara keseluruhan masih bisa berfungsi dengan baik.
- Skalabilitas: MoE dapat menangani masalah yang semakin kompleks dengan cara membagi tugas ke dalam komponen yang lebih kecil dan mudah dikelola.
Baca Juga: Mengenal Apa Itu Website AI: Cari Tahu Fitur dan Contohnya
Kesimpulan
Mixture-of-Experts (MoE) adalah pendekatan revolusioner dalam dunia machine learning, memungkinkan model AI seperti DeepSeek bekerja lebih efisien dan lebih akurat.
Dengan membagi tugas ke dalam beberapa expert spesialis, MoE mampu mengurangi beban komputasi, meningkatkan fleksibilitas, dan mempercepat inferensi.
Jika kamu ingin mengembangkan proyek berbasis AI atau machine learning, pastikan kamu memiliki infrastruktur yang andal.
IDwebhost menawarkan layanan VPS Murah dengan performa tinggi untuk mendukung pengembangan website dan aplikasi AI-mu secara optimal.
Dengan server yang stabil dan fleksibel, kamu bisa fokus membangun solusi AI terbaik tanpa khawatir soal performa hosting!
Related Articles

